【Power BI入門】家計簿分析レポート#3 ~スタースキーマの概念でデータモデル設計をする~

この記事は「Power BI入門 家計簿レポート」シリーズの第3回目で、Power BIのデータモデル設計の考え方を解説しています。

Power BIのデータモデル設計…どうやって考えればよいのですかな…?

まずは、Power BIのデータモデル設計に必要な「スタースキーマ」の概念を学んでいきましょう!
前回の第2回では、「何を知り、何を判断したいか」、家計簿データ分析の要件を整理しました。

今回は家計簿レポートを作成する際の、データモデル設計をしていきます。
- Power BIのデータモデル設計の進め方
- スタースキーマとは?
- ファクトテーブル・ディメンションテーブルの考え方
Power BIについて詳しく学びたい方は、ぜひパワ実のPower BI入門書もご参考ください!

YouTube動画で見たい方は、こちらからどうぞ!
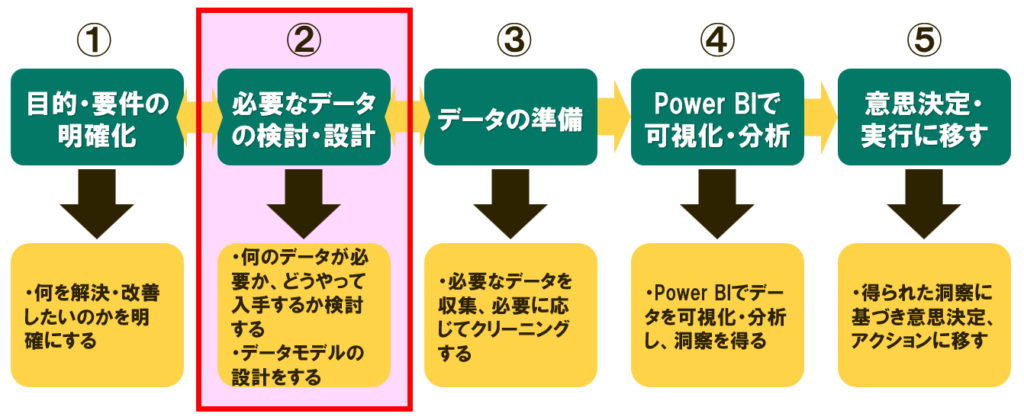
今回実施するところ
このシリーズでは、Power BIを使ったデータドリブンな意思決定の流れを学ぶことができます。
今回は②必要なデータの検討・設計の後半部分にあたる、「データモデルの設計」を進めていきます。
データモデル設計の流れ
データモデルの設計は、次の4つのステップで進めます。
- 必要なデータの一覧を洗い出す
- ファクトテーブルと、ディメンションテーブルに分ける
- テーブルの列、カラム定義をする
- リレーションシップを設計する
この4つのステップを順番に進めることで、Power BIに適したデータモデルが設計できます。
データモデル設計をするため、Power BIで重要な「スタースキーマ」という概念を理解することがポイントになります。
スタースキーマとは?
次に、スタースキーマという概念を説明します。
スタースキーマとは、値を持つテーブルに対して、複数の切り口テーブルが、多対一で紐づくデータモデルのことです。
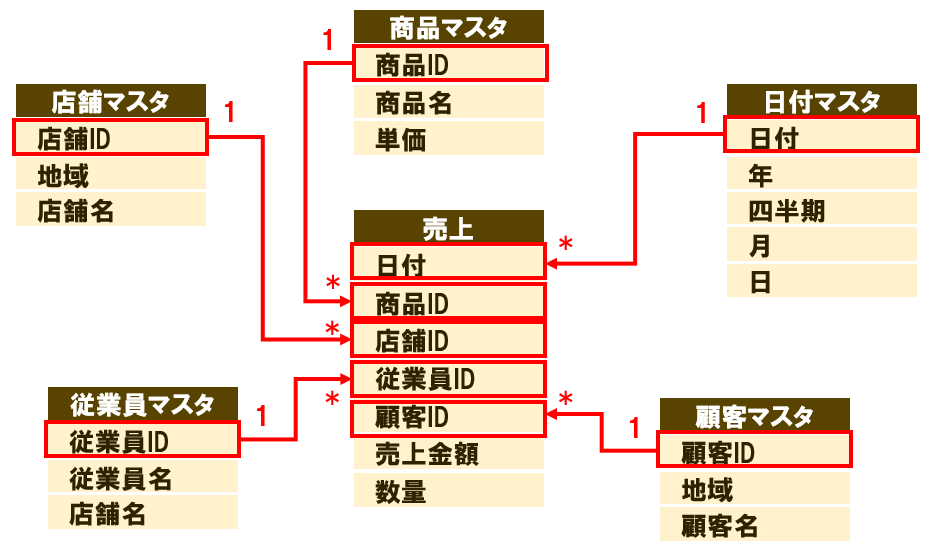
- 中央の「売上」テーブルは、ID等のキー列や、売上金額・数量という数値列を持っている。
- 売上テーブルに対して、「商品マスタ」「日付マスタ」「店舗マスタ」「顧客マスタ」「従業員マスタ」という、5つのマスタテーブルが紐づいている。
- 売上テーブル:各マスタテーブル=1:多(*)の関係性となる。
図の「1」と「*」という記号は、リレーションシップの1と多を表し、1側がマスタテーブル、多側が売上テーブルです。

つまり、「1つの商品に対して、売上は複数件ある」という関係ですな!
この構造が、中心から星のように広がって見えることから、スタースキーマと呼ばれています。
先ほどの図で、「値のテーブル」と「切り口のテーブル」という表現を使いましたが、 Power BIでは、以下のように呼びます。
- ファクトテーブル:売上金額や数量など、数値データを持つ「値のテーブル」
- ディメンションテーブル:商品・日付・顧客などのマスタ情報を持つ「切り口のテーブル」
図では、中央の「売上」がファクトテーブル、まわりの5つのマスタがディメンションテーブルです。
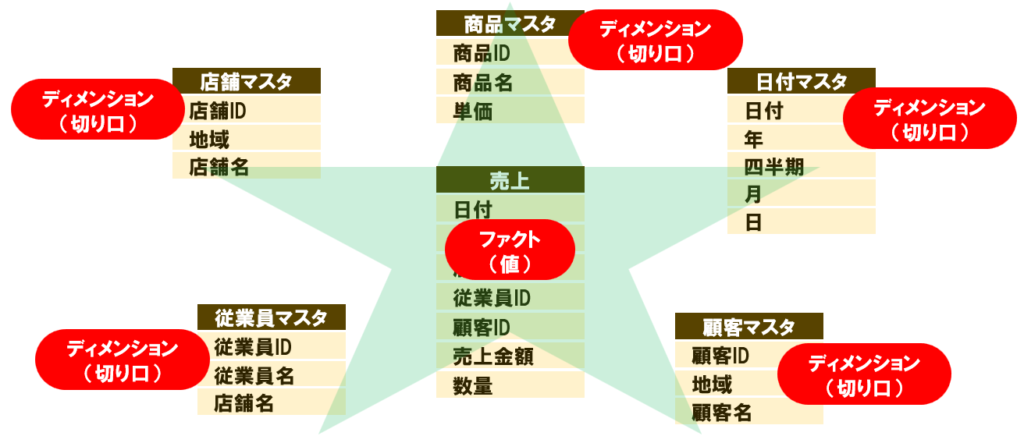
この「ファクト」と「ディメンション」という言葉は、今後も使いますので、覚えておいてください!
ファクトテーブルとディメンションテーブルの違いを、もう少し整理します。
ファクトテーブル
- 販売額・注文数・気温のような「値データ」を持つテーブル
- Power BIのレポートで、グラフの「値」フィールドに設定する列を持つ
ディメンションテーブル
- 商品・場所・日付のような「切り口データ」を持つテーブル
- Power BIのレポートで、グラフの「軸」や「凡例」、「スライサー」に設定する列を持つ
この考えは、Power BIでレポートを作るときに、各テーブルに、何の列を入れるかを検討するときに役立ちます。

「ファクト=値、ディメンション=切り口」というイメージを持っておくことが大切ですな。
スタースキーマの概念については、以前の記事も参考にしてください。

データモデル設計をする
①必要なデータを確認する
最初に、必要なデータを確認します。
前回(第2回)で定義したKPI(知りたい指標)は、一番左の列にあげた5つです。

この表では、各KPIに対して、必要な列と、使用するファイルをまとめています。
例えば「総収入・総支出・貯蓄率」を計算するには、日付・金額・収支区分の列が必要で、収支履歴のCSVファイルから取得するということですな!
「NISA将来金額」については、投資信託CSVの評価額を使い、将来の予測値はDAXという数式で算出します。これは後の回で詳しく解説しますね。
このように、KPIから逆算して、必要な列とファイルを整理することが、データモデル設計ではじめに行うことです。
②テーブルをファクト/ディメンションに分ける
ここからは、実際に家計簿データを、ファクトとディメンションに分けていきます。
まず、手元にある3種類のCSVファイルを確認します。
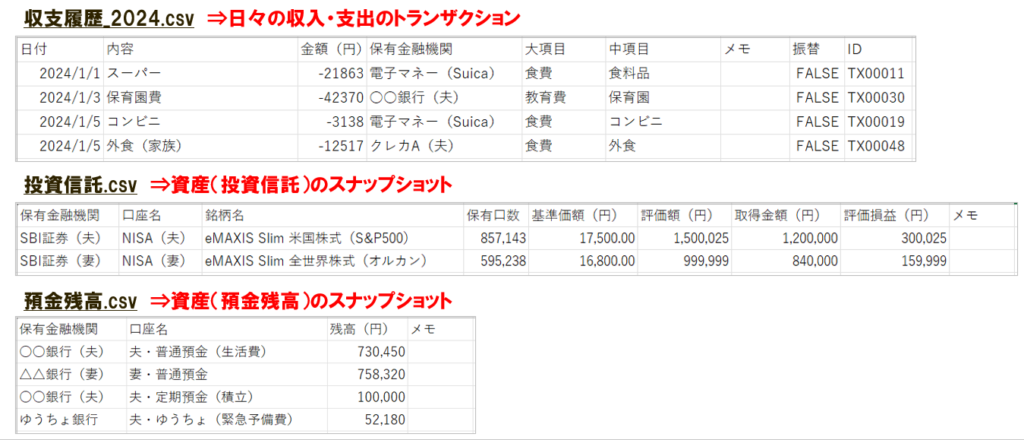
- 収支履歴:日々の収入・支出のトランザクション(取引の記録)
- 投資信託:保有している投資信託の評価額などのスナップショット(特定時点の残高データ)
- 預金残高:銀行口座の残高のスナップショット
データの性質を最初に確認することで、どのテーブルがファクトになり、どのデータからディメンションを切り出すかが見えてきますな。
次に、各CSVファイルから必要な列を一覧にして、ファクトとディメンションの列を判別します。
以下のように、クリーム色の列がファクト(値の列)で、緑色の列がディメンション(切り口の列)です。
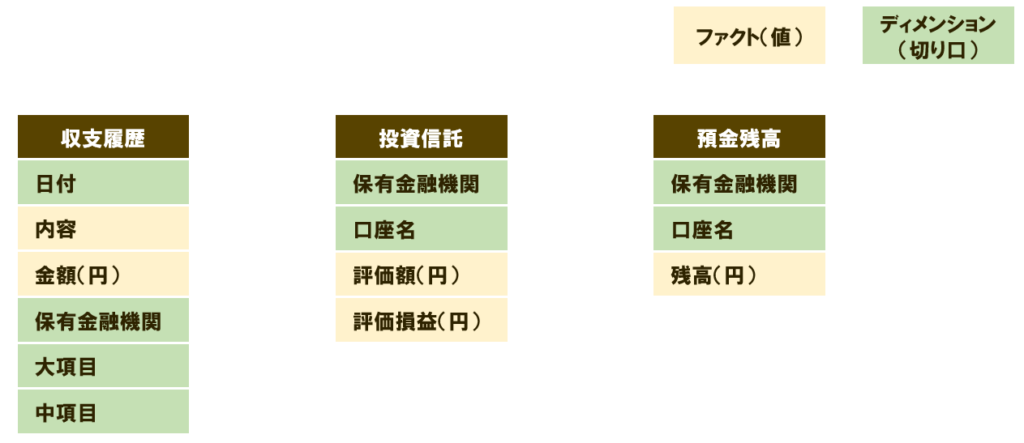
このように、列ごとに「値か切り口か」を分類することで、ファクトと、ディメンションテーブルへの分け方が見えてきます。
この列の分類をもとに、元のCSVデータをファクトテーブルとディメンションテーブルに分割・統合していきます。
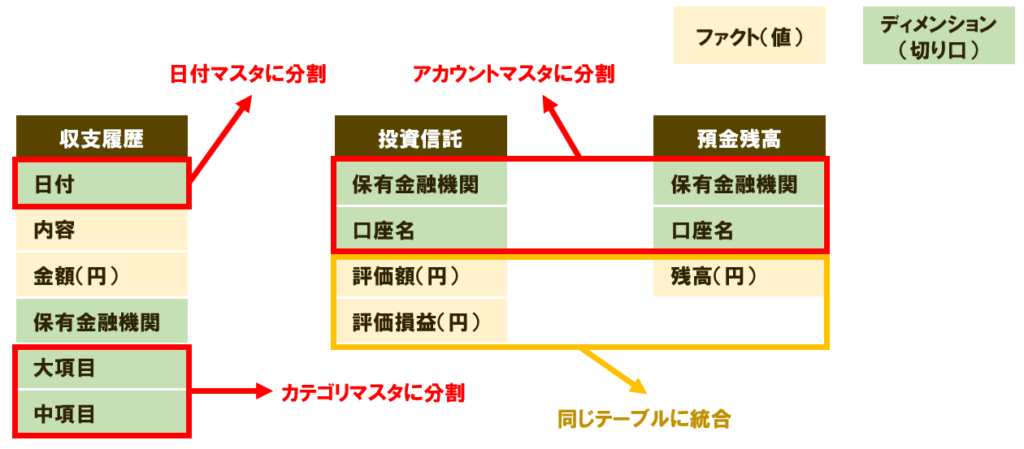
- 収支履歴の「日付」列は、独立した「日付マスタ」として切りだす
- 「大項目」「中項目」は、「カテゴリマスタ」に分割
- 「保有金融機関」は、収支履歴・投資信託・預金残高の3ファイルに共通しているので、「アカウントマスタ」として統合
- 投資信託と預金残高は、どちらも「資産残高のスナップショット」という同じ性質を持っているため、1つのファクトテーブルに統合
このように、元データをそのまま使うのではなく、スタースキーマの構造に合わせて分割・統合することが、Power BIでのデータモデル設計の重要な作業になります。
分割・統合の結果、最終的なテーブル構成は次のようになります。
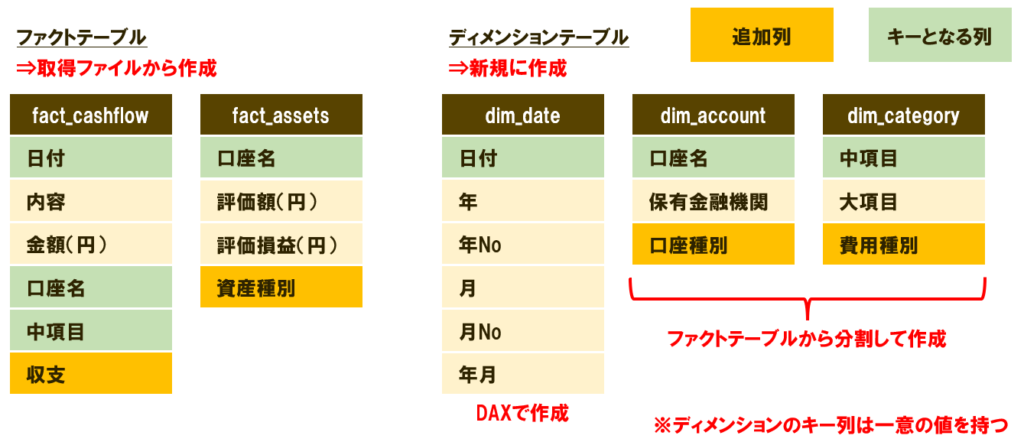
ファクトテーブル
- fact_cashflow:収支履歴 ➡収支履歴CSVから作成
- fact_assets:資産のスナップショット ➡投資信託と預金残高のCSVから作成
ディメンションテーブル
- dim_date:日付マスタ ➡DAXの関数式で自動生成
- dim_account:アカウントマスタ ➡ファクトテーブルから分割
- dim_category:カテゴリマスタ ➡ファクトテーブルから分割
これで5つのテーブルに分割されました。

このテーブル構成がスタースキーマの骨格になります。
③カラム(列)定義をする
次に、各テーブルのカラム定義(列名とデータ型)を整理します。
まずファクトテーブルは、以下のようにカラム定義をしました。

データ型を明示しておくことで、Power QueryやDAXで扱うときに型の不一致によるエラーを防ぐことができますぞ。
特に、金額や評価額は「整数」、「10進数」、「固定小数点」等で定義しておくことが重要です。
続いてディメンションテーブルは、以下のようにカラム定義をしました。

これで全5テーブルのカラム定義が揃いました。
④リレーションシップを設計する
最後に、テーブル間のリレーションシップを設計します。
スタースキーマでは、ディメンションテーブルのキー列と、ファクトテーブルの対応する列を1対多で紐づけます。
今回の設計では図のようなリレーションシップになります。
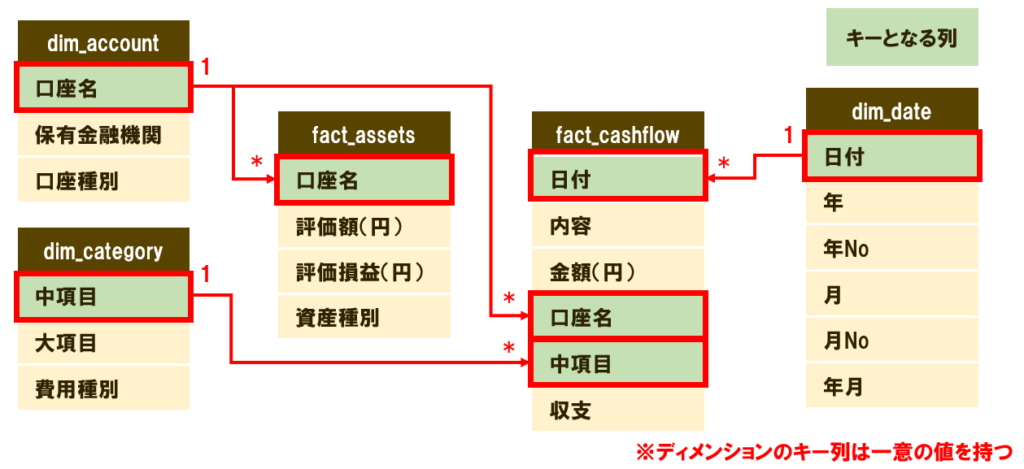
図の赤枠はキーとなる列(リレーションシップの結合に使う列)を示しています。
「1」側がディメンションテーブル、「*」側がファクトテーブルです。
※「fact_assets」は日付のないスナップショットデータのため、dim_dateとは繋ぎません(常に取得した最新データを表示するイメージ)。
このようにして、Power BIのデータモデル設計ができました。
次回以降、このデータモデル設計を目指し、Power Queryでのデータ変換をしていきます。
さいごに
この記事は、「Power BI入門 家計簿レポート」シリーズの第3回で、家計簿データ分析のデータモデルを整理していきました。
スタースキーマとは、ファクトテーブルと、ディメンションテーブルに分けて、多対一のリレーションシップを作成するデータモデルです。
今回は、収支履歴・預金残高・投資信託の3種類のCSVを、5つのテーブルに整理してデータモデルを設計しました。

次回はいよいよ、Power BI Desktopを操作しますぞ!
今回設計したデータモデルをもとに、Power Queryを使ってCSVファイルを取り込み、データのクレンジング・変換処理を行っていきます。
次回もぜひ見ていただければと思います!










